
Die in KISSKI geplanten Forschungsarbeiten dienen dazu, die Effizienz bei der Nutzung der Infrastruktur des Servicezentrums zu steigern und die Nutzenden darin zu stärken, KI anzuwenden. Die Forschung ist in vier ineinandergreifenden Forschungsthemen gegliedert und unterstützt das Servicezentrum: bei einem Erfolg in der Forschung werden entstehende Prototypen von Mitarbeitenden bei den Services aufgegriffen und integriert, um die Services weiter zu verbessern.
Skalierbares KI-Training und hochverfügbare Inferenz für sensible Daten
Die Skalierung zeitkritischer KI-Modelle ist insbesondere in der Betriebsführung und Planung von Energienetzen, im Energiehandel, sowie bei akuten medizinischen Diagnostikaufgaben von großer Bedeutung. Entscheidend ist eine zuverlässige Einhaltung einer zugesagten Time to Completion (TTC) bei der Inferenz.
Teil-automatische Skalierung von KI-Modellen
Große Datenmengen sind der Schlüssel zu guten KI-Modellen. Workflows für das maschinelle Lernen werden aber oftmals von den Nutzenden für kleinere Datensätze auf einer Workstation entwickelt. Die Umstellung von einer einzelnen Workstation auf effizientes paralleles Training in einem Hochleistungsrechner ist eine Herausforderung. KMUs haben hier zudem einen Wettbewerbsnachteil, da die Verarbeitung großer Datenmengen kostenintensiv ist. Sie sind besonders auf kosteneffiziente Strategien zum Lernen aus größten Datenmengen angewiesen. Hierzu werden grundlegende Modelleigenschaften, wie die Netzwerkarchitektur von Deep-Learning Modellen, untersucht und ihre Leistungsfähigkeit, Ressourcenaufwand und Interpretierbarkeit abgeschätzt sowie Modell-Hyperparameter festgelegt.


Ausnutzung heterogener Hardware für KI-Modelle
GPUs bieten eine effiziente parallele Architektur für das Training und die Inferenz und sind daher bei der Nutzung von KI-Modellen weit verbreitet. Es gibt jedoch weitere Architekturen, wie Graphcore Beschleuniger, FPGA oder Google TPU, welche in vielen Fällen effizienter sind. Neuromorphe Chips wie Intels Loihi versprechen eine weitere Effizienzsteigerung bei niedrigem Energieverbrauch. Für einen Vergleich ist die einfache Portierung eines KI-Workflows auf verschiedene Architekturen zeitaufwändig und führt nicht immer zu einem fairen Ergebnis. Oft sind Verbesserungen durch weitergehende Anpassungen möglich, bspw. kann bei FPGAs Rechengenauigkeit gegen Geschwindigkeit eingetauscht werden. Hingegen benötigen neuromorphe Systeme speziell angepasste Algorithmen, die den Einstieg für Nutzer:innen deutlich erschweren, aber signifikante Verbesserungen in Energieverbrauch und Trainings- und Inferenzzeiten ermöglichen.
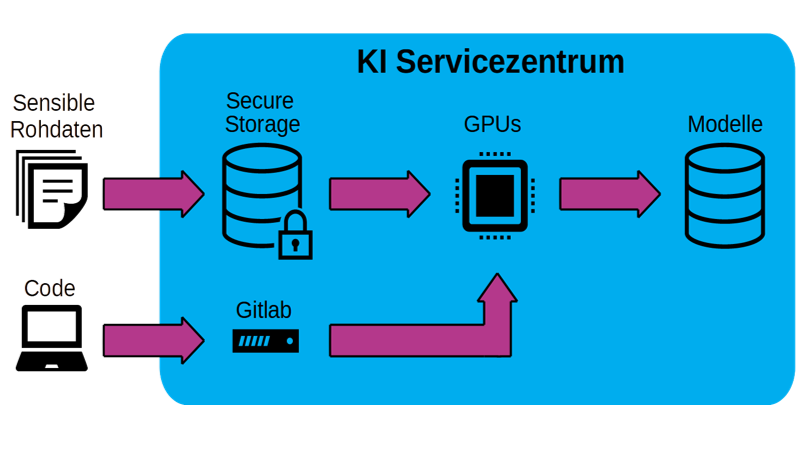
Sicheres und effizientes Datenmanagement
Das Management von Trainingsdaten ist aufgrund ihrer Eigenschaften (5-Vs: Volume, Velocity, Variety, Veracity, Value) eine Herausforderung. Wünschenswert ist sowohl eine zentrale Dateninfrastruktur mit Data Governance zur Gewährleistung von Qualität, Integrität und Sicherheit (Datenschutz, Vertraulichkeit) der gespeicherten Daten, als auch die Einhaltung der FAIR-Prinzipien (findable, accessible, interoperable, re-usable), wodurch Nutzer:innen Datensouveränität über ihre multimodalen Daten und Zeitreihen erlangen. Stattdessen wird typischerweise eine projektspezifische und oftmals minimalistische Werkzeuglösung verwendet. Dies führt zu Dateninseln (Data Silos) und erschwert den Austausch von Daten drastisch. Die besondere Herausforderung in KISSKI ist, dass der einfache und effizient skalierbare Zugang für berechtigte Nutzer:innen einhergehen muss mit dem benötigten Schutz gegen unberechtigte Zugriffe. Die KISSKI Data Governance muss daher einen Workflow etablieren, der basierend auf aktuellen Verschlüsselungstechnologien, sowie dynamisch allokierbaren, isolierten Rechenknoten sicheres und skalierbares Prozessieren der Daten ermöglicht.
