
The research planned in KISSKI is designed to increase efficiency in the use of the service centre’s infrastructure and to empower users to apply AI. The research is divided into four interrelated research themes and supports the service centre: where research is successful, emerging prototypes will be taken up and integrated into the services to further improve them.
Scalable AI training and highly available inference for sensitive data
The scaling of time-critical AI models is particularly important in the operational management and planning of energy grids, in energy trading and in acute medical diagnostic tasks. Reliable adherence to a promised time to completion (TTC) during inference is crucial.
Semi-automatic scaling of AI models
Big data is the key to good AI models. However, machine learning workflows are often developed by users for smaller data sets on a workstation. Moving from a single workstation to efficient parallel training in a high-performance computer is a challenge. SMEs are also at a competitive disadvantage here, as processing large amounts of data is cost-intensive. They are particularly dependent on cost-effective strategies for learning from large data sets. For this purpose, basic model properties, such as the network architecture of deep learning models, are investigated and their performance, resource requirements and interpretability are estimated, and model hyperparameters are defined.


Exploiting heterogeneous hardware for AI models
GPUs provide an efficient parallel architecture for training and inference and are therefore widely used in the exploitation of AI models. However, there are other architectures, such as Graphcore accelerators, FPGA or Google TPU, which are more efficient in many cases. Neuromorphic chips like Intel’s Loihi promise further efficiency gains with low power consumption. For a comparison, simply porting an AI workflow to different architectures is time-consuming and does not always lead to a fair result. Often, improvements are possible through further adaptations, e.g. with FPGAs, computational accuracy can be traded off for speed. Neuromorphic systems, on the other hand, require specially adapted algorithms that make it much more difficult for users to get started, but enable significant improvements in energy consumption and training and inference times.
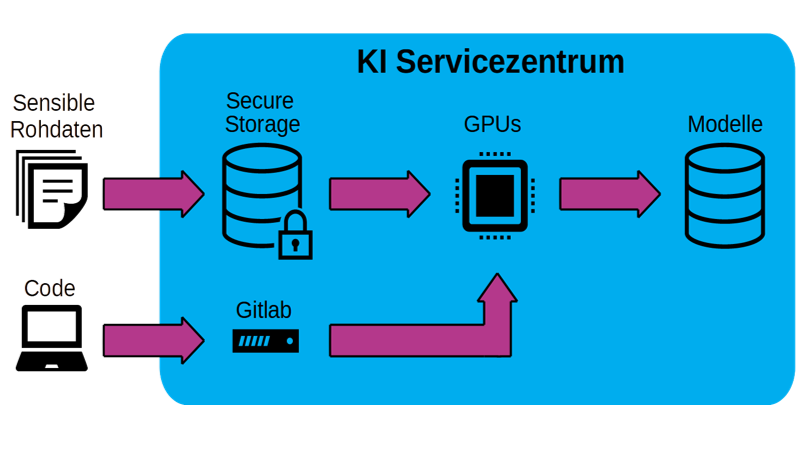
Secure and efficient data management
Managing training data is challenging because of its properties (5-Vs: Volume, Velocity, Variety, Veracity, Value). It is desirable to have a central data infrastructure with data governance to ensure quality, integrity and security (data protection, confidentiality) of the stored data, as well as compliance with the FAIR principles (findable, accessible, interoperable, re-usable), whereby users gain data sovereignty over their multimodal data and time series. Instead, a project-specific and often minimalist tool solution is typically used. This leads to data silos and makes the exchange of data drastically more difficult. The particular challenge in KISSKI is that simple and efficiently scalable access for authorised users must go hand in hand with the necessary protection against unauthorised access. KISSKI data governance must therefore establish a workflow that enables secure and scalable data processing based on current encryption technologies and dynamically allocatable, isolated computing nodes.
